Implications of a Perfect AI Engineer
2025-02-17
As many of you may know (considering that you are on my website), I am a computer nerd. Most importantly, 90% of my awake time is spent on either shipping new features to my company or learning about computer technology. In terms of computer technology, I feel like I have some authority when discussing this domain. (I have written my own optimized C compiler for the amd64 architecture, deployed over countless auto-scaling cloud infrastructures, and have deployed countless ML models that are currently being commercially used; I am also currently doing research at Carnegie Mellon to speculatively convert scalar programs into vector programs at runtime).
Anyways, the current AI climate has been occupying my brain space recently. I am here to discuss my thoughts and perhaps stimulate some of your thoughts too.
The main topic of discussion is whether AI will ever be able to be a perfect engineer. While semantically simplistic, I believe this question is rather important. To unpack this thought, we must first define what a perfect engineer means. For the sake of this discussion, we will be taking software engineering as the primary field (our thoughts here can be extrapolated to other fields).
The perfect software engineer means the ability to produce a commercially working software 100% of the time, regardless of the number of iterations it takes. The extra attention to mentioning that large amounts of iterations is permitted is very important as software engineering is naturally an iterative process.
Now, why is the idea of a perfect engineer so significant? Well I believe whether or not this perfect engineer can be created can cause a massive paradigm shift in the business world. If this perfect engineer can be indeed created, then the SaaS world would be eliminated. Anyone would simply need to tell the AI what features they want in their software and it would be shipped within an acceptable time frame. Now, if the perfect engineer cannot be created, then AI would simply be just an extremely powerful tool that will allow engineers to work at 10x if not 100x efficiency. The SaaS world would simply become significantly more competitive, but software would still hold immense value as it does today.
I personally think that it is pretty hard to evaluate the likelihood of this happening, but we can analyze several key facts. First and foremost, AI has run into a pretty similar problem as multicore processors (dark silicon issue) where we have run into somewhat of a ceiling. This is also called the "Efficient Compute Frontier" for AI. In essence, we are seeing significant diminishing returns relative to the size of the training corpus as well as compute power. Of course, this is all relative to the current paradigm of AI models.
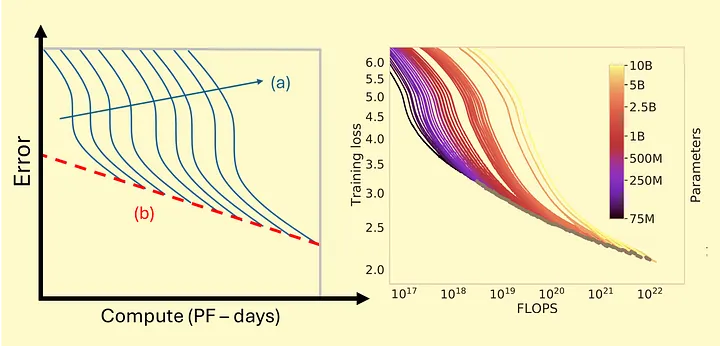
Left: Schematic plot illustrating the efficient compute frontier. The blue curves (a) illustrate increasing model sizes that require more compute to achieve lower error rates. The red dashed line (b) represents the efficient compute frontier, beyond which additional compute yields diminishing returns in performance improvements. Thus, while larger models can improve performance, they are ultimately constrained by the efficient compute frontier, where further scaling becomes computationally impractical. Right: Training error reduces predictably with compute across a broad range of empirically-studied training runs, panel shows exponential increase in training compute for OpenAI's GPT models from 2018 to 2023 (Hoffman et al, 2022)
While pessimists will say that we are hitting something of an endgame for LLMs, which could entirely be true, if we manage to invent a superior model than the current LLMs and LRMs (Large Reasoner Models) we could very much witness another jump in AI intelligence. It is also important to note for the non-technical reader that LRMs (o1, o3, deepseek) are really just LLMs with lower convergence proclivities in order to escape potential local minimas.
DeepSeek's research has also yielded a major insight for the average joe. With improved techniques, current state-of-the-art models can be trained by competitors with significantly less compute power. The cost for these LLMs and LRMs will only continue to go down. It also seems like the cost of inference is going down. If the development of neuromorphic chips really becomes significantly better, the cost of inference will only continue to drop significantly which makes it more sustainable both environmentally and economically. Whether or not this translates into the ability to produce even better models, we are not sure. However, there does seem to be a promise of lower prices in the near future. What we are basically promised, however, is significantly more tokens to input into the current models given the decreased cost of inference. This would allow AI models to accommodate significantly bigger contexts to work with, providing greater ability to work on highly contextual work.
We should also bring our eyes to the recent declaration of the $500 Billion Stargate project. I personally think that OpenAI can definitely invent a new type of AI model that beats the current state of the art LLMs and LRMs if they pour their money into the right channels. Regardless, the idea of a perfect AI engineer is scary yet tantalizing for the world, and whether even a 99% AI engineer can be made is still a mystery.